Fiddler是一款免费好用的web debugging工具,可用于网络抓包。下面简单介绍Fiddler再抓包过程中的过滤功能。
Fiddler支持解析HTTPS请求,不过首先需要再Fiddler设置,设置之后会自动安装Fiddler的根证书。
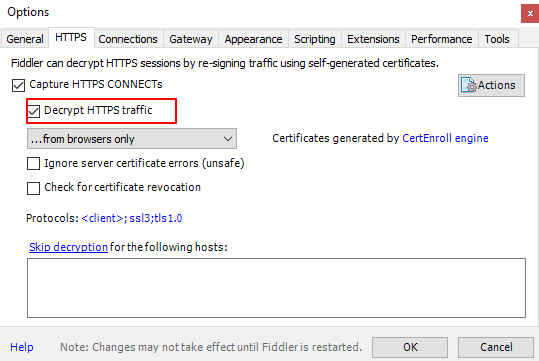
在Filter页面,勾选Use Filters,对filter进行一定的配置,然后点击右上角的Actions
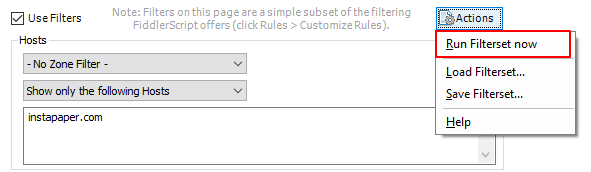
即可以按你配置的规则进行包过滤。
在使用过滤时,自己也踩了不少坑。想当然的以为这个功能不是“显而易见”嘛,然后就发现,咦,我的包哪去了??下面简单说下遇到的“坑”。
坑1:以为可以自动匹配三级域名
例如,如果你想只抓取instapaper.com站点的数据,需要在host下填入:www.instapaper.com,而不是直接填写instapaper.com。在不使用通配符的情况下,Fiddler默认是使用完全匹配的规则来进行过滤的,也就是说在host为instapaper.com的过滤条件下,是无法在结果中显示www.instapaper.com的数据包的。
对于这种情况,可以使用通配符来匹配Host名称,如*.instapaper.com;*instapaper.com。
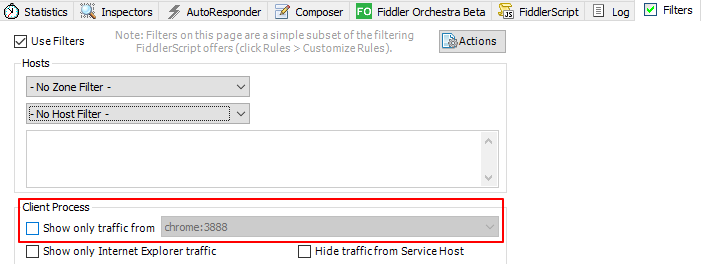
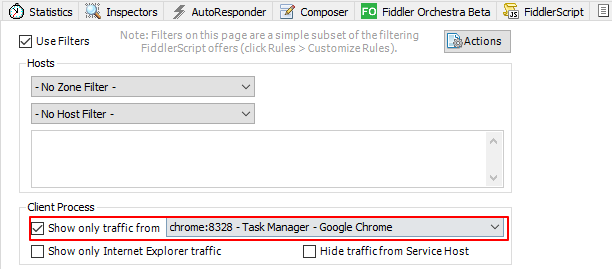
坑2:以为Chrome的Task Manager中的Process ID作为过滤条件
在Fiddler中过滤页面中,可以通过Process ID作为过滤条件,如下图:
在Chrome中的Task Manager中可以看到Tab的进程ID的,如下图:
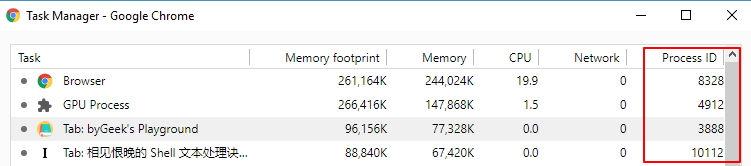
但是注意了(手动划重点!):如果想要在Fiddler中使用Client Process ID作为chrome的Tab的数据包的过滤条件的话,这个process ID并不是在task manager中的Tab的process ID,而是Chrome 浏览器的Process ID,即在上图中Browser的Process ID。
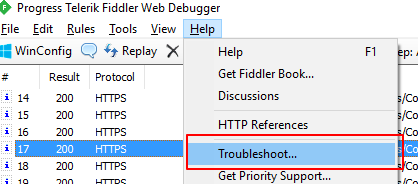
打开TroubleShooting
如果发现在使用Fiddler的过滤时,无法正确的Filter到想要的包,可以在打开Fiddler的TroubleShooting,查看包时被什么过滤条件给“无视”了。
勾选之后,Fiddler会将所有的包都已“被划掉”的形式显示出来,并在Comments一栏显示被”无视”的原因。

Happy Fiddlering!